
1. Language recognition for Arabic, Chinese, Korean, Japanese, Latin and Russian

- Category: Computer vision
- Client: HUAWEI TECHNOLOGIES CO., LTD
- Project date: 2019
SegLink with DenseNet results visualization
Pretrained on SynthText dataset






Goal
Complete Task 1 and either Task 2 or Task 3
- Task 1: Improve detection for Arabic
- Task 2: Improve recognition for Arabic
- Task 3: Improve recognition for Chinese
Results
Goal: Complete 1st task and at least one of 2nd or 3rd tasks
- Task 1: Improve detection for Arabic (completed)
- Task 2: Improve recognition for Arabic
- Task 3: Improve recognition for Chinese (completed)
Task 3 specifications
- Improve HQ solution [for Chinese and English recognition] by 3% (end-to-end)
- Model should meet NPU restrictions
Results for Chinese and English recognition
Solution elements:
- Baseline architecture
- Advanced learning techniques
- Improved training data selection
| Solution | F1-score |
|---|---|
| Baseline (NLPR) | 0.908 |
| GlobalML | 0.939 |
Task 1 specification
- Provide single detection model for Arabic, Chinese, Korean, Japanese, Latin, and Russian languages
- For Arabic for Kirin 980 Precision/Recall ≥ 94/92% accordingly
- For Arabic for Kirin 970 Precision/Recall ≥ 92/90% accordingly
- No negative affect on detection of other scripts
- Model should meet NPU restrictions
- Model size in Cambricon format ≤ 12 Mb
Task 1 specification reformulated
- Provide single detection model for Arabic, Chinese, Korean, Japanese, Latin, and Russian languages
- For Arabic for Kirin 980 Precision/Recall comparable with other languages
- For Arabic for Kirin 970 Precision/Recall comparable with other languages
- No negative affect on detection of other scripts
- Model should meet NPU restrictions
- Model size in Cambricon format ≤ 15 Mb
Solutions for detection
Solution Elements:
- Seglink model combined with DenseNet
- AdvancedEAST model
- Trained on Batch2+arabic dataset
- Both models are on Keras, .pb graphs were extracted
Results for all scripts
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.84 | 0.86 | 0.82 |
| AdvancedEAST | 0.85 | 0.97 | 0.76 |
| Baseline (HQ) | 0.82 | 0.92 | 0.76 |
Results for Arabic
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.77 | 0.71 | 0.84 |
| AdvancedEAST | 0.83 | 0.9 | 0.76 |
| Baseline (HQ) | 0.67 | 0.73 | 0.61 |
Results for all languages
| Language (Script) | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Arabic | 0.83 | 0.9 | 0.76 |
| English (Latin) | 0.86 | 0.96 | 0.77 |
| French (Latin) | 0.84 | 0.98 | 0.74 |
| Russian | 0.75 | 0.96 | 0.62 |
| Italian (Latin) | 0.88 | 0.98 | 0.79 |
| Chinese | 0.93 | 0.99 | 0.88 |
| Korean | 0.84 | 0.96 | 0.75 |
| Portuguese (Latin) | 0.78 | 0.98 | 0.65 |
| German (Latin) | 0.83 | 0.98 | 0.72 |
| Japanese | 0.81 | 0.97 | 0.69 |
| Spanish (Latin) | 0.85 | 0.97 | 0.75 |
Model weights
| Model | Weights size (MB) | Estimated size after quantization (MB) |
|---|---|---|
| Seglink on DenseNet | ~50 | ~14 |
| AdvancedEAST | ~60 | ~15 |
2. License plate recognition system
- Category: Computer vision
- Client: Municipal Client
- Project date :2021
- Description: A system for traffic flow analysis and license plate recognition under various conditions.

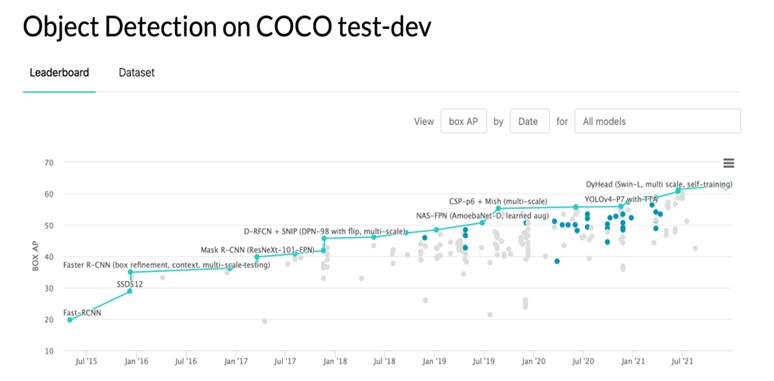
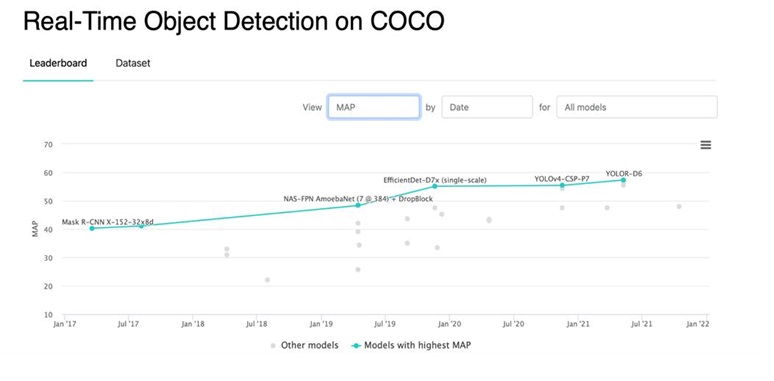
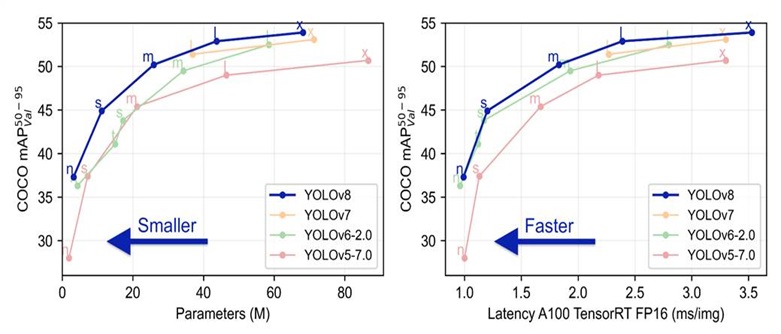
Comparison of different versions of the YOLO model by mAP (50-95) metric on the COCO dataset
License plate recognition algorithms typically consist of two components: a localization (detection) component that identifies the portion of an image containing the relevant information, and a character set generation component that extracts characters from the selected area.
To select the detection model, a thorough analysis of literature was conducted, identifying the best models in terms of both speed and detection accuracy. The YOLOv5 model was determined to be the optimal choice at the time, offering comparable accuracy to SOTA models while delivering impressive performance.
Similarly, an analysis of literature was conducted to explore SOTA models for text recognition from images (OCR). Although there are various solutions based on the Transformer architecture, they often exhibit slower performance. As a result, the CRNN model was identified as the most suitable model for the task.
The existing dataset was transformed to retrain the YOLOv5 model, which involved ten epochs of training to observe the desired improvements.
Subsequently, the retrained YOLOv5 model was utilized to construct a dataset consisting exclusively of license plate images. Annotations for the numbers were obtained from the original dataset. The CRNN model was then retrained on this modified dataset, achieving a recognition accuracy of 96% on the test sample.
The YOLOv5 (detection) and CRNN (recognition) models were integrated into a library component for license plate recognition from a video stream, seamlessly integrating with the existing library architecture. During the development of this module, ultralytics released several YOLO models. The YOLOv8n version, with comparable detection accuracy to YOLOv5s but fewer parameters and higher speed, was incorporated into the algorithm and further fine-tuned for license plate recognition.
To ensure maximum stability of the algorithms in adverse weather conditions, image augmentation methods and projective geometry techniques were implemented. Augmentation is the process of enriching a set of data by generating their “distorted” versions. Several types of distortions were implemented:
- Shifts
- Turns
- Glare
- Defocus
- Compression and tension
- Color (for simulating night filters)
Augmentation of the available datasets made models more resistant to various weather conditions.
To evaluate the algorithm's performance in challenging weather conditions, an additional 357 test images of cars (captured under poor lighting, snow, rain) were collected and labeled using the Roboflow service. Examples of such images:

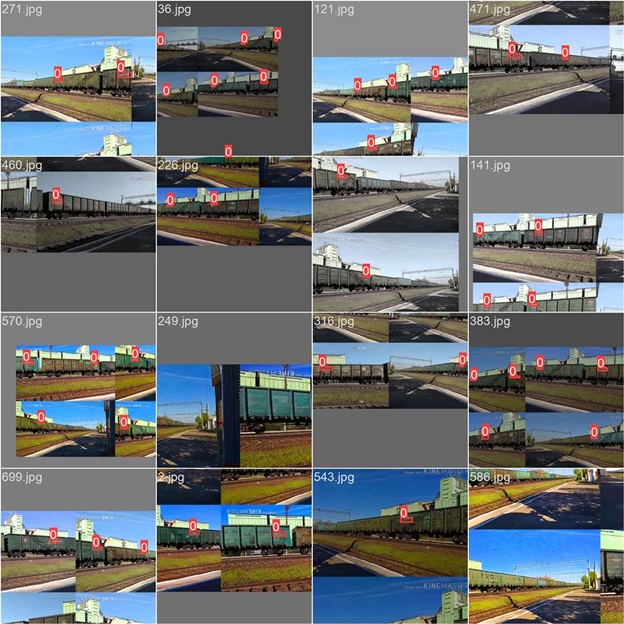
3. Train car number recognition
- Category: Computer vision
- Client: Transportation Company
- Project date: 2022
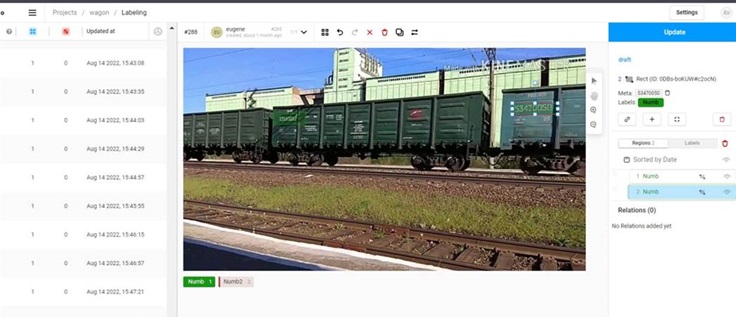
Creating training examples from natural images involves collecting real data through various means:
- Collection of images (photographing objects of interest, capturing a video stream from a camera, highlighting a part of an image on a web page).
- Filtering - checking images for a number of requirements: adequate object illumination, the presence of the target object, etc.
- Preparing annotation tools (developing custom annotation tools or optimizing existing ones).
- Marking (selecting rectangles or regions of interest in the images).
- Assigning a label to each image (letter or name of the object in the image).
As part of the initial project phase, data collection was organized, including photographing and recording passing trains under various conditions. The collected data was then labeled using the Label Studio tool, marking the coordinates of the bounding rectangle for each car number.
The detection (YOLOv8) and recognition (CRNN) components were subsequently retrained on the collected dataset for car number recognition. The overall recognition accuracy on the test sample was 89%, indicating that the model correctly recognizes all characters of the number in 89% of cases. This result demonstrates the model's ability to generalize well to related problems, which can be further improved with additional labeled examples.
4. QR and barcode recognition system
- Category: Computer vision
- Client: Commercial Client
- Project date: 2022



Results of analysis
Existing solutions for QR and barcode recognition were considered. Running the OpenCV library with the zbar algorithm revealed that QR codes are generally detected more effectively than barcodes of the same size. The results of the analysis on read quality are presented in Figure and further discussed below.
Empirical observations indicated that complex QR codes begin to be detected and read correctly when they occupy approximately 0.8% of the frame, while simpler codes require around 0.64% of the frame. Codes below approximately 0.74% for complex QR codes and 0.57% for simple ones were no longer reliably detected.
Barcodes, on the other hand, face challenges due to the closely spaced bars, which often result in blurred frames. Unlike QR codes, barcodes can be partially read even if horizontally cut off to some extent, though the data might be incomplete. For instance, some frames might read an area as small as 0.04% of the frame, while detection might not work correctly below 0.74%. If over 0.91% of the area is present during the detection and not cut off, the codes are recognized with clarity and completeness.
In experiments, the distance from which all codes were easily detected was determined (QR codes with sizes of 1.26 cm for simple ones and 1.55 cm for complex ones). When rotated at an angle of 43 degrees, the codes were no longer readable. However, when the rotation angle was reduced to 40 degrees or less, all codes were correctly read. The transition point from complex code unreadability to simple code readability could not be precisely identified, as both occurred around the same time.
For barcodes, the distance from which all codes were easily detected was determined (barcode sizes approximately occupying 0.96% of the frame). When rotated at an angle of 43 degrees, the codes were no longer readable. At a rotation angle of 40 degrees, not all codes were read successfully, and those that were read had detection errors, resulting in incorrect readings. Starting from a rotation angle of 33 degrees, everything became readable, but occasional detection errors began to occur. When rotated at 30 degrees or less, everything was read correctly.
Based on the satisfactory results achieved using the OpenCV library with the addition of the zbar library, the decision was made to adapt the existing solution.
5. Free-Form Text Recognition System
- Category: Computer vision
- Client: Industrial Client
- Project date: 2022
- Description: Recognition of text of arbitrary form, various fonts, markings, inscriptions in conditions of various noise levels and for various alphabets



To compare the performance of existing character recognition libraries, namely PaddleOCR, Tesseract, Doctr, and EasyOCR, a dataset of 1210 photographs of produced objects (metal, plastic, glass, brick, paper, wood) was collected. The average Levenshtein distances between the recognized inscriptions and the ground truth were calculated for various material categories, as presented in Table:
| Material/Model | PaddleOCR | Tesseract | Doctr | Doctr |
|---|---|---|---|---|
| Metal | 0.057160 | 0.461613 | 0.268681 | 0.181886 |
| Brick | 0.353260 | 0.041227 | 0.335991 | 0.103651 |
| Glass | 0.307380 | 0.254498 | 0.270838 | 0.212571 |
| Plastic | 0.947816 | 0.210128 | 0.147302 | 0.017100 |
| Paper | 0.377727 | 0.223795 | 0.270136 | 0.135312 |
| Wood | 0.055672 | 0.189703 | 0.188016 | 0.014465 |
| Miscellaneous | 0.124016 | 0.045473 | 0.021668 | 0.031424 |
The results revealed that a significant error factor stems from incorrect text position detection within the image. To address this, an external detector, the YOLOv8 small model, was employed for text detection. However, the initial weights yielded unsatisfactory results. To further enhance its performance, a synthetic dataset comprising 10,000 photographs of industrial premises featuring text in various Latin and Cyrilic fonts was generated for additional training.
Based on testing results with real-world data, the algorithm achieved an accuracy of 0.3, which is dependent on the conditions of photographing the numbers on objects. The photos need to be clear and captured in good lighting. The angle of text inclination should not exceed 20 degrees, and the text must occupy at least 1.5% of the frame for successful recognition. Vertically written text cannot be recognized reliably, while numbers written on plastic, glass, paper, and cardboard yield the best recognition results.